
For a few years now, everyone has been talking about migrating our data and applications to the cloud, and it is something normal, I would say even natural. Once the stigma of security has been saved, and the skepticism on some companies to remove their data or applications from those bunkers called datacenters, the reality is that the benefits offered by the cloud are difficult to overcome in a local environment. Application re-engineering may be required, however (and this is where DBcloudbin can help, as we will see later).
Cost savings is one of the main benefits, savings in physical infrastructure (servers, network elements, …), savings in management and maintenance of the same infrastructure and savings at the software level (for example, avoiding the acquisition of licenses), are some of the most attractive benefits of moving to the cloud. But its benefits are not exclusively monetary, our applications, data, servers, etc., will also benefit from a complex set of mechanisms and flows that will make them more scalable, secure and with high availability.
From Tecknolab, and through our DBcloudbin solution, we help our customers to take this step, migrating in a simple, secure and transparent way binary data (documents, images, …) from their databases to the main Cloud providers. Reducing your databases and therefore the cost of infrastructure, management and protection of them.
But what if, for example, we already have data in the cloud in an S3 repository or similar and we want to exploit it from an application outside of it?. The obvious and simple answer would be: make the necessary modifications in your application, to be able to interact with the cloud storage systems, using the protocols and APIs that the same providers provide (Amazon S3, Google Cloud, Azure…). Many times this process of reengineering the data access layer of an application is not easy at all, even sometimes the complexity of the application itself, as in legacy applications, makes it unfeasible. In addition, this type of process usually entails certain costs that are difficult to bear for a project of these characteristics.
Therefore, discarding this point, and based on the principle of simplicity, what is likely is that said application already uses a database, and that, if the application already supports binary data processing, its data is capable of supporting such functionality. This is where the nibdoulocbd (DBcloudbin flipped over) project comes in.
The nibdoulocbd project

The nibdoulocbd project is based on a “reverse engineering” of the cloud data, after which and using DBcloudbin as a solution, we will be able to make our application able to have visibility of this data, without a custom cloud integration; maybe with slight modifications in case it is not prepared for the treatment of binary data (which will always be less expensive than having to fully implement an S3 connector, for example). This process will not move the data from the cloud (a priori it is not what we are interested in, although we could even do it through DBcloudbin if necessary), but it will make it accessible from our application in a transparent way.
An example from the real world.
In addition, once DBcloudbin is installed in our systems, it will not only allow us to access existing data in the cloud, but it will also provide us with the tools of the solution working in “non-inverse” mode, allowing us to archive or restore data to and from the cloud that are stored in the database of our application.
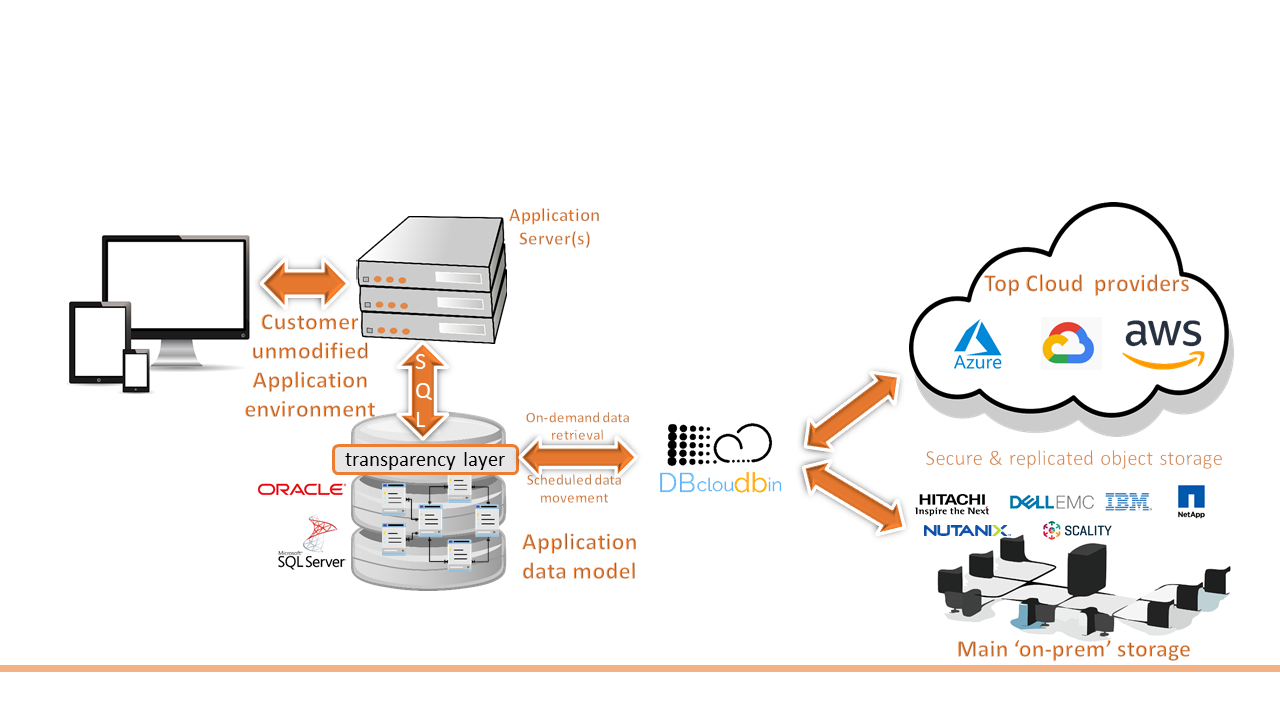
In a future post, we will provide a hands-on implementation description of this example. Meanwhile, for more details of the solution, visit https://www.dbcloudbin.com/solution