

A large-scale dataset stored in an Enterprise DB (usually Oracle) with a multi-TB volume of binary data, represents a fantastic opportunity for huge cost savings using DBcloudbin but, at the same time, is a challenging scenario as in any massive data migration project out there. We need to massive-data-migration-automation. We will do a introduction to this scenario in this post and how DBcloudbin automation framework is able to handle all the process.
Let’s assume we have a large scale database with TBs of binary data and we have successfully installed DBcloudbin. For a quick introduction on the solution basics, check our DBcloudbin for dummies post; for high-level overview on the install process, check here; for the complete details, you can register and get the install guide.
With the solution implementation we get a functional environment where the customer application is able to access the data from the database as before, regardless of whether the data is hosted inside the database or moved out to a more efficient and cheaper object storage. However, after implementation we have 100% of the data still hosted at database, so we have to do the ‘heavy lifting’ of moving all our binary dataset. In a regular DBcloudbin implementation we will typically define a data migration rule to be executed recurrently (usually daily) for moving the data based on our specific business rule (e.g., reports with status ‘X’ and more than ‘y’ days old). This is fine for dealing with the new data that lands in our environment in a daily basis but for a massive historical migration will not be valid, since we may need weeks to move all the data. So, we need a different strategy for massive data migration.
We have created a simple yet effective mechanism for massive data migration automation where we provide the following artifacts:
- A simple framework, leveraging DBcloudbin configuration engine and DBcloudbin operations & activity dashboard for the foundational pieces of defining the migration plan and monitoring it.
- A set of automation scripts that can be used to configure and automate the migration process, while feeding the results to automatically update the monitoring dashboard with the progress and potentially any issues that would require further analysis or troubleshooting.
The method, in a nutshell, is:
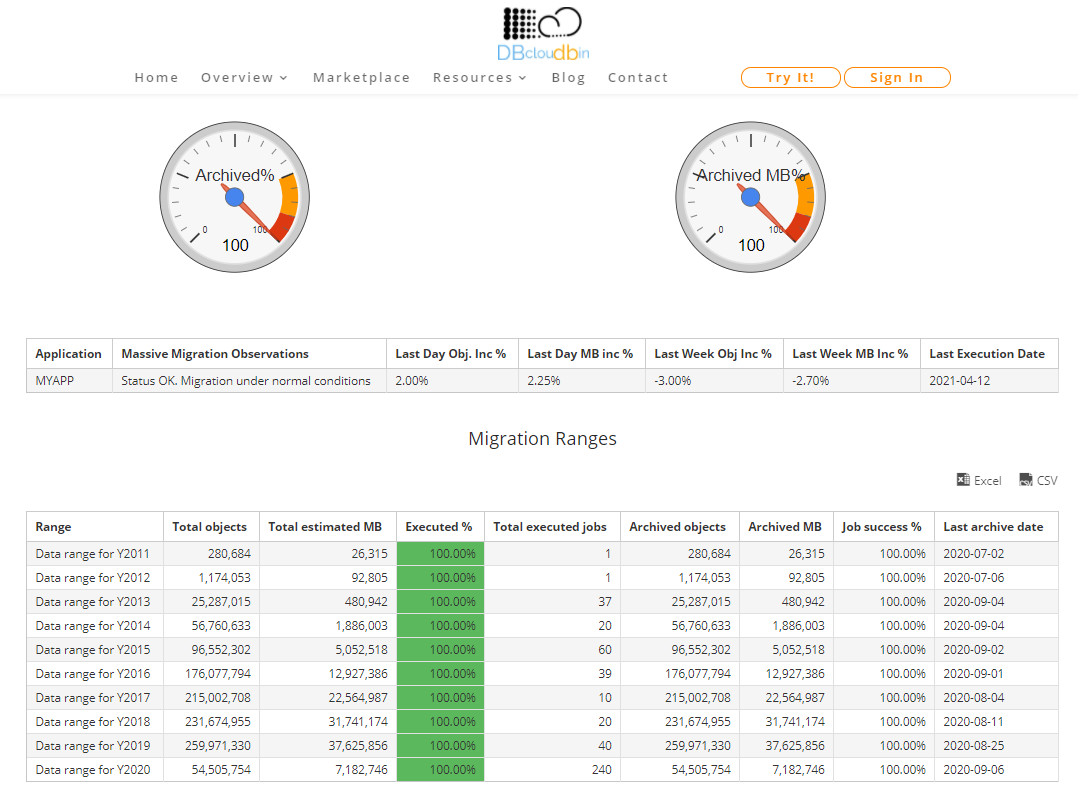
- We should analyze and split our to-be-migrated data by batches. This is not strictly required, but very convenient for monitoring and scheduling purposes. For example, we can define batches by historical criteria (documents from year XX). Once identified, we can create an csv file with the batches list, including inventory data as the total number of objects and total data volume per batch. This is easily created with a simple SQL query through your dataset. With that csv file we can ask DBcloudbin support team to setup the Massive Migration Dashboard with our batches definition.
- We download the massive migration framework from the link provided by DBcloudbin support in the response to the previous request. The framework comprises basically a simple user guide with the parameters to configure in our DBcloudbin environment (they are regular parameters with just specific id’s that start with the prefix “x.” and help us to tune the framework behavior (we will explain it later). So we simply leverage the high available, distributed configuration engine of DBcloudbin for setting the relevant parameters for our migration strategy. This way, we can scale horizontally our implementation with additional DBcloudbin nodes and automatically they will handle and share all the migration settings. This is very important for quickly adapting our migration throughput to our expectations depending on the computing power we have available (we recommend using virtualized infrastructure for additional flexibility).
- Configure the massive migration script (from the framework) for daily scheduling in our DBcloudbin nodes (usually in a simple cron configuration). Since the script will use the settings at the configuration layer, it is basically inmutable and you are not expected to change the cron configuration during the whole migration project.
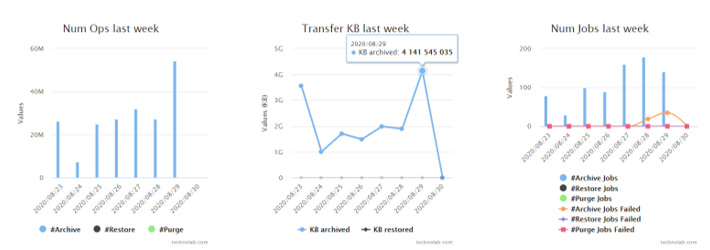
- Test and monitor the logs. If all is OK, our daily migration runs will be automatically consolidated in the Massive Migration Dashboard in our DBcloudbin website customer area (it is provisioned when we request the framework in the step 1). There, we have a simple but informational dashboard on how our migration tasks are doing, the migration rates per batch, the failed jobs and the expected complete time.
Configuring the migration settings
As described above there are a series of configuration settings that we can use to customize how we want to handle the massive migration:
- Active/Inactive: This is a global switch that we can use to stop/restart our migration jobs. This way, we can temporarily stop the migration in all our migration nodes (that may be many) from a central point.
- Filter: This is where we define the logical expression for the objects that define the active batch. If we want to migrate objects for the batch “Year2010” that represents the historical documents from Y2010, we need to define here the ‘where’ clause in our data model that would select the documents for this year (may be something like “EXTRACT(year FROM document.creation_date = 2010)” ).
- Batch: The batch id should match the filter criteria by one side and the batch id we defined in our csv of batch definitions. So, if we decided to split our batches by historical year of data and named in our csv file the 2010 batch as “Y2010”, this parameter should be set as “Y2010”. This way, the DBcloudbin massive migration backend is able to identify this migration statistics to the specific batch and aggregate the statistical data in the migration dashboard.
- Core settings: There are a number of additional settings that will usually not be changed during the migration project (but they can be modified when required, of course):
-
- Table name: The table that contains our to be migrated data. We should configure the engine in a ‘per-table’ basis if we have more than one.
- Migration window duration: We can set the maximum allowed time for a migration run. This way we can configure the process to run only in low workload periods (e.g. nightly runs). The framework will automatically stop and start again the next day at the point where was interrupted and statistics will be aggregated without any manual intervention. This can even be tuned for labour and weekend days to configure different migration windows.
- Number of workers: We can define the parallelization level for each migration job in order to tune the migration throughput depending on the computing and networking capacity of our environment. This may also require some tuning depending on the average object size of our data (the smaller the object the better a high number of workers for maximize throughput). DBcloudbin support will provide guidance on this.
- Log files directory & options: Where we want to store the detailed activity and error logs (and if we want to log performance counters for tweak or troubleshoot performance issues). This will be normally used only for detailed troubleshooting of migrations errors that are recorded in the Migration Dashboard.
- Errors threshold: In massive highly parallelized migration jobs is normal to receive errors from the object store platform we are using for migrating the content to. DBcloudbin is very conservative in errors and, by default, a job is aborted if any error is produced. In massive migration jobs where we are executing jobs that are expected to work during several hours this is not convenient (an object write error does not produce a specific problem, the transaction is rolled-back at database level and the object keeps secured stored at the database). This setting will allow us to define a higher threshold sol we will only consider a migration job as ‘failed’ if it trespass this threshold.
Using this framework we have successfully executed massive data migration projects. If you want to check in greater detail one example, we suggest requesting our Billion+ objects project whitepaper, where it is technically described the migration of a large Exadata platform with more than a billion objects.