
In a previous post we discussed about the potential use of DBcloudbin in a reverse way: not for moving content to Cloud but to make Cloud content available to regular (potentially legacy) apps through its relational database. In this new post we will explain in greater detail the technique, with a sample app using Oracle.
The “nibdoulocbd” project consists of using our DBcloudbin solution in an reverse way, to provide our applications with access to documents that we already have stored in the Cloud, with minimal modifications in our application and in our data model. Let’s go with the details…
To carry out this “reverse re-engineering” process, we have selected one of the demo applications provided by the Oracle APEX development platform, but this process could be carried out on any of our applications running on Oracle or SQL Server. For simplicity, we configured an Oracle APEX environment on Docker; you can follow the following tutorial.
Once we have configured our environment with Oracle Apex 5.4 with a workspace called DEMO, it is time to get down to work. The first thing we will do is access our DEMO workspace through the APEX URL, in our case http://localhost:8080/apex/:
We see the application on which we will base this example “Sample Database Application” that is a sample business application able to manage sales orders (if it does not appear directly, you can install it from the Packaged Apps tab).
Data Model modification
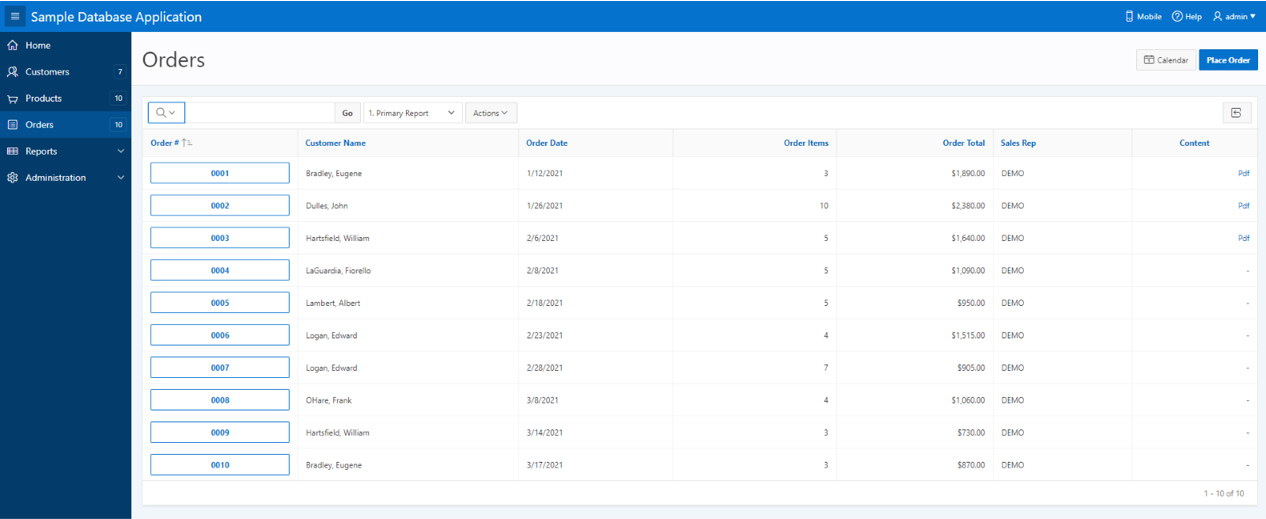
APEX is obviously designed for easy handling of data through the database, but at this point we do not have an attribute (a BLOB type) in the database representing our external Cloud content, so we will have to modify our data model to treat binary data. We would like the user to be able to access the purchase orders in PDF format that we have stored in a S3 bucket in the Cloud from the “Orders” tab in our application; this way our application will handle in the same tab the ‘order data’ already processed with the pdf that we have received with actual order document. This seems a good feature to have.
For this, the only necessary modification in our data model will be to add the necessary fields to the DEMO_ORDERS table to achieve this purpose. This will be as simple as executing the following SQL statement from our preferred SQL client on the DEMO schema.
Application Modification
NOTE: This is not required in a regular DBcloudbin implementation. In our “flipped over” sample scenario we need it because our application is not currently handling documents (binary content), so we need a minimal application enhancement.
In this section, we will modify our Demo application so that it is able to access and show the user the data “stored” in the columns that we added to our model in the previous step. To do this, we access the APEX App Builder menu. After selecting the edition mode of our application “Sample Database Application”, the design window of our application will appear.
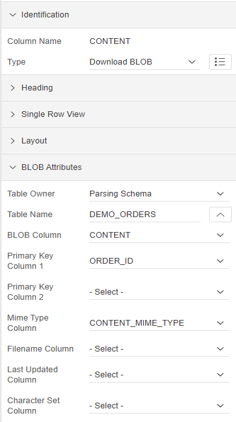
We select the page to modify, in this case our “Orders” page. Once inside the page designer, we will select the Content Body / Orders section, where we will modify the SQL query to show a new column on the page with the link to our PDF documents. We add the following line to the existing SQL statement, which will allow the application to have visibility of the new CONTENT column:
We save the modifications and the new CONTENT column will appear as part of the Content Body of the “Orders” page. When selecting this field in the properties screen we will see the following values:
With these simple steps our application will be ready to access documents stored in our database. But, as we commented previously, the idea was not to access the binary data directly in our database, but rather that what we wanted was to access our documents stored in the cloud, and thus avoid the loading in our database , occupying a huge and unnecessary amount of space in it. This is where DBcloudbin comes into the picture, after a quick and simple installation (you can find how to carry out said installation in the following link), and by selecting the DEMO_ORDERS table as the table managed by the solution, we can access the data of our storage in the preferred cloud (Amazon S3, Google Cloud, Azure,…).
To finish this short tutorial and have access to the cloud data, we will have to perform two last actions:
The first, and as part of the DBcloudbin installation / configuration process, we must modify the configuration of our application so that it uses the new transparency layer generated by the DBcloudbin installer (previously it must have been made visible to APEX from its administration panel). To carry out this modification in our Demo application, we will access its edition menu, from the “App Builder” tab and select the option “Edit Application Properties”:

Where, within the “Security” tab, we can modify the scheme to be used by the application. Therefore, we will modify this scheme so that the application uses the transparency layer generated by DBcloudbin: DEMO_DBCLDBL. After this minimal configuration change, the application will be using the transparency layer generated by DBcloudbin to access the data, accessing it, in the same way as it did until now (without internal modifications of queries or other hassles).
As a last step, and since the movement of data to the cloud has NOT been managed by DBcloudbin, to have access to them, we must manually add the links to each of the PDF documents we want to access. To do this, we must insert these links in the DEMO_ORDERS_DBCLDBL table, belonging to the DBcloudbin transparency layer. In our particular case and assuming that the name of the PDF documents stored in the cloud is the purchase order identifier, we can make a simple insertion with an SQL statement similar to the following:
Where the <bucket_path> is the path in our S3 bucket where the documents are located. Once we have all the links inserted in the transparency layer, the documents will be perfectly accessible from our application as if they were contained within the same database:
Hope you find interesting this alternative usage of DBcloudbin solution.