

DBcloudbin 3.04 added some new and cool functionalities to our solution. If you need a basic understanding on what DBcloudbin is before going through the new features, you have a solution overview section that cover the fundamentals and a DBcloudbin for dummies post series that goes one step back using a less technical language. For the “why DBcloudbin?” you may want to review our DBcloudbin vision post.
In version 3.04 we are introducing some important features that enhances our vision of simplicity and automation:
- Archive/Delete automation: Until version 3.03.x, archiving operations must be launched with DBcloudbin commands (CLI) manually or in a regular way with your preferred scheduler. With version 3.04.x, we offer an “install and go” solution, usable from the very first second, introducing the Archive/Delete Automation feature. When activated during setup or through configuration, DBcloudbin will automatically archive the new inserted or updated data; and/or delete (with the configured lagging days) the application deleted objects (both archive and delete can be activated independently). This feature can be enabled globally or at table level, so it allows us to activate the auto archive mechanism only for desired tables. This feature does not disable the current archive mechanism, so, for example, we could launch archive jobs manually to migrate the old data, and let the system automatically archive new data with the auto archive functionality enabled.
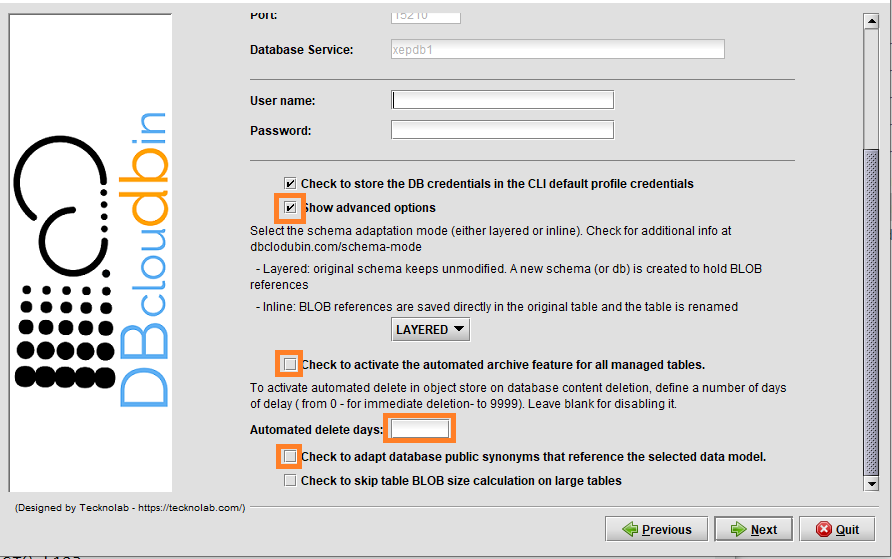
- Public synonyms redirection: DBcloudbin in default mode, creates a new schema (database in SQL Server) for the transparency layer avoiding any change in your original application data model. Depending on your application data layer design, it may not use a single database user for accessing the application data, but several ones (potentially one per application user), referencing the tables and other database objects through public synonyms. In this case, the way to ‘activate’ DBcloudbin is not changing the database connection but changing the affected synonyms to point to the transparency layer instead of to the application schema. This operation might be cumbersome and error prone when addressing complex schemas. DBcloudbin v3.04 addresses this problem with a new option (as highlighted in the previous screen), to automatically reconfigure the existing public synonyms pointing to the application schema. This way, after DBcloudbin setup, the environment will be ready for archive operations without any additional reconfiguration. As a bonus benefit, in the case of uninstalling DBcloudbin, the reverse operation will be also automatically executed.
- Metadata enrichment: In current times, metadata is very important, since it adds value to our data, allowing us to classify, analyze, search and a long list of additional operations that we could carry out with our data. The vast majority of object store infrastructure out there, support some type of metadata assignment to stored objects, that can be leveraged by different analysis tools with the strong benefit of offloading that work from the main application database. For this reason, with this new version, DBcloudbin allow us to add custom metadata defined by the user and based in SQL syntax queries over our database information. The metadata mechanism will allow us to define metadata form the DBcloudbin CLI tool (with -metadata option), with simple queries over the target table or more complex queries using the -join option to obtain metadata from different tables. Also, we could define alias for our metadata, using an expression like the following: {MY_ALIAS}. Additionally, the solution will store a Json file in the same object store path with, not only the custom metadata, but also the Built-in metadata associated to the original object. An example for that could be:
CLI example
In the previous example we are assuming that our table “MYTABLE” has an attribute “CONTENT_NAME” that we want to be mapped in our object store with its value in the tag “FILENAME”; the same for “CREATOR” (table attribute) and AUTHOR (object store tag name). This is the simplest way of metadata enrichment. The solution is more versatile. It supports any valid SQL expression, not only plain attributes. So if we are using Oracle and the attribute CONTENT_NAME may have uppercase and lowercase characters and we want our tag to hold only uppercase, we may use the following command:
Using expressions
And there is more. Sometimes we need complex expressions or values where part of the information is not stored at the table we are archiving content from. For enabling that content, you can use a JOIN expression that logically links that data with the specific row in the to-be-archived table content. So if in the previous example, “CREATOR” in table MYTABLE is just and internal id, but the real creator’s name is in the table CREATORS we could use the following archive command:
Using joins
Special shortcuts like @PK (will define the complete primary key as metadata) or @ALL (will define all the target table fields as metadata) are allowed to define metadata in a simpler way.
Special shortcut expressions
- Improved monitoring: We have included all auto archive information in the DBcloudbin CLI info command, adding last execution information like the total processed objects and execution time or the specific error messages if something is wrong. To get it, we will use the -verbose option. Additionally, this new version includes the -format json option to get a Json friendly output, very useful for scripting and automation processes.
- Docker/Kubernetes support: New version comes with the support of containerized packaging for our agent and CLI, so that it makes it very simple to deploy DBcloudbin agent in Kubernetes clusters or Docker environments. We will discuss this in greater detail in a specific post in our blog.
There are some other minor features that can be checked in our release notes but these are the most relevant.