
by | | blog

IT communications for business impact
In information technology, your ability to convey complex concepts in a language everyone can understand is not just a skill but a necessity. For IT professionals, bridging the gap between technical prowess and effective communication ensures that your work stays relevant and receives the recognition it deserves. DBcloudbin is a very technical IT solution that falls in this scenario, so this guide will show you how to articulate your IT contributions in a way that resonates with non-technical stakeholders, ensuring your message is heard and appreciated.
Encourage Learning
In the ever-evolving realm of IT, the commitment to continuous learning stands as a cornerstone of professional growth. Encouraging the pursuit of a computer science degree online, along with other certifications, serves not only personal advancement but also significantly augments your ability to communicate effectively.
Such educational endeavors expand your horizons, offering fresh insights that refine your skills in conveying intricate ideas in simpler terms. This relentless pursuit of knowledge demonstrates your unwavering dedication to your field and enhances your capability to illuminate the marvels of technology for the world at large.
Know Your Audience
Understanding who you’re talking to is the first step in effective communication. Dive deep into your audience’s backgrounds, knowledge levels, and interests to craft messages that speak directly to them. By doing this, you’re not just sharing information but engaging in a conversation tailored specifically to their perspective. This approach makes your message more relevant and more likely to be understood and acted upon.
Simplify Complex Information
The essence of clear communication lies in your ability to simplify. When discussing IT concepts, minimize the use of jargon and acronyms. If you must use complex terms, immediately follow them with a simple, relatable explanation. This practice ensures your message remains accessible, removing barriers to understanding and fostering a more inclusive dialogue about your projects and their impact.
Use Analogies
Making technical concepts relatable is a powerful tool in your communication arsenal. By drawing parallels to everyday experiences or objects, you demystify technology, making it easier for non-technical stakeholders to grasp. This method not only enhances understanding but also makes your message more engaging, helping to capture and maintain your audience’s interest.
Employ Visual Aids
Visual representations can transform your communication, making complex data or processes instantly more comprehensible. Utilize charts, graphs, diagrams, and other visual tools to break down information into digestible pieces. This approach not only clarifies your message but also adds a layer of aesthetic appeal that can make your communication more memorable.
Focus on Impactful Metrics
In the realm of IT, success is often measured in numbers. Highlight Key Performance Indicators (KPIs) and metrics that matter to your audience to demonstrate the effectiveness of your projects. Choosing metrics that align with non-technical stakeholders’ goals and interests ensures that your achievements are not just seen but understood and valued.
Tell a Story
Narrative is a potent tool for making your technical achievements resonate. Frame your IT contributions as stories with a clear beginning, middle, and end. This approach adds a human element to your communication, making complex achievements more relatable and memorable. Stories help contextualize your work, showing its impact in a way that numbers alone cannot convey.
Promote Dialogue
Finally, fostering an environment where questions are welcomed and knowledge is shared openly encourages a deeper engagement with your message. Inviting dialogue allows your audience to delve deeper, ensuring your communication is not just a monologue but a conversation. This openness enriches the understanding of your work while building stronger, more collaborative relationships with your stakeholders.
Effective communication in IT goes beyond simply sharing information; it’s about making your work accessible, understandable, and relevant to everyone. By tailoring your message, simplifying complex concepts, using relatable analogies, employing visual aids, focusing on impactful metrics, telling compelling stories, encouraging ongoing learning, and fostering open dialogue, you ensure that your IT achievements don’t just speak for themselves—they sing.
Hope our recommendations will help you as it helped us building DBcloudbin. Check our solution today at dbcloudbin.com!
Article written by Cherie Mclaughlin.

by | | blog
Navigating the complex demands of today’s digital landscape leaves many small business owners stretched thin across multiple responsibilities. Outsourcing specific tech-related tasks can provide much-needed relief, allowing you to focus on your core business objectives. In this article, Tecknolab (the DBcloudbin manufacturer) explores the top tech tasks best left to the experts, so you can concentrate on driving your business forward.
Elevate Your Brand Through Graphic Design
In the world of digital marketing, a strong visual presence can make or break your brand. Graphic design is an essential element in shaping how your audience perceives you. Outsourcing these tasks to skilled professionals allows you to tap into their expertise, thereby elevating your brand’s visual identity. For example, a bakery might outsource its packaging design to make its products more appealing. Various software is frequently used by graphic designers to bring your vision to fruition.
Harness the Power of User-Friendly Software
Utilizing user-friendly software solutions empowers small businesses to take control of their promotional needs, allowing for the creation of promotional material with unique designs. You can effectively showcase your business offerings without breaking the bank by leveraging tools like online brochure makers. This DIY approach provides a cost-effective alternative to outsourcing while still ensuring a professional touch to your brand’s presentation. Moreover, these software options often come with customizable templates, allowing you to align the designs closely with your brand identity.
Outsource Content Creation
In today’s digital landscape, top-notch content is key to engaging customers and establishing your brand’s voice. Outsourcing to professional writers allows for a uniform, high-quality narrative across multiple platforms. Platforms like WordPress facilitate the seamless management and publication of this outsourced material.
If content size becomes a management problem in the data repository, DBcloudbin may be a choice for easy management and database size reduction.
Automate to Streamline Operations
Embracing automation technology can lead to massive time efficiencies while simultaneously reducing operational costs for your business. Workflow automation platforms excel at streamlining repetitive tasks, freeing up your team to concentrate on more critical aspects such as customer service or product development. Take, for example, a veterinary clinic that deploys automation tools to handle appointment scheduling and reminders; this liberates the staff to devote more time to the well-being of their animal patients.
Prioritize Cybersecurity
In our digital-first world, cybersecurity is more critical than ever, making outsourcing to specialists an invaluable decision for businesses. Take an online educational platform, for example, which would gain robust protection of sensitive student data through expert system monitoring and firewall installations. These experts often utilize technologies like VPNs and secure cloud storage to safeguard against cyber threats. Take a look at DBcloudbin’s security solutions.
Simplify Business Formation
Navigating the intricate legal and tax requirements of starting a business can be daunting, but outsourcing these tasks offers a streamlined solution. For instance, a tech startup may outsource intellectual property registration and compliance to remain focused on innovation. A formation service like Zenbusiness is available to manage these responsibilities, easing the administrative burden on new entrepreneurs.
Improve Financial Acumen
Financial oversight is crucial for business success, and outsourcing to experienced accountants can elevate your operation. For example, a small marketing agency might outsource financial management to focus on core business activities like project execution. These professionals can deliver precise bookkeeping and valuable financial insights using cloud-based financial software.
Enterprise owners require fast and accurate financial reporting for business decision making. This can be achieved as well with outsourced solutions such as Tecknolab’s InfoRoot business intelligence for small and midsized businesses (SMBs).
Master Digital Marketing
In today’s fiercely competitive online environment, outsourcing your digital marketing to skilled professionals can give your business a significant advantage. For instance, a restaurant could leverage experts to amplify online reviews and spearhead dynamic social media campaigns. Technologies such as Google Analytics and CRM platforms serve as invaluable tools for measuring the success of these outsourced strategies.
Outsourcing tech-related tasks offers a myriad of benefits for small business owners, ranging from time savings to enhanced productivity and specialized expertise. By implementing the insights and recommendations offered in this article, you stand to improve the chances of your business achieving long-term success considerably. This approach allows you to focus on what you excel at, setting the stage for growth and scalability.
Article written by Cherie Mclaughlin.

Tech Efficiency Unleashed

by | | blog
Why dockerizing DBcloudbin (or any application)? The answer is simple and clear: from DBcloudbin we want to make life easier for our users, and Docker is the way to do it. Here are some reasons that support this idea:
- Container provisioning/deprovisioning is extremely easy for users.
- Avoid third party software installations or software dependency problems (with java versions for example).
- Make the solution more flexible, scalable and cloud-friendly deployment (allowing DBcloudbin deployments in cloud application platforms like Kubernetes).
- Simplify version upgrades: It would be as easy as launch a new container with the new docker image version.
The running components that make up a DBcloudbin installation are mainly two:
- DBcloudbin agent, to process all the requests launched by the CLI or indirectly by your application through SQL queries.
- DBcloudbin CLI tool, to launch the common tasks as executing archive or purge operations.
Since version 3.04 we are packaging and publishing in Docker Hub both components as images to be used as docker containers. IMPORTANT! This will not avoid the usage of DBcloudbin setup to configure the Database layer and adaptation of your application schema using the regular DBcloudbin install tool (you can request a FREE trial here). However you can install only the first two packages running the setup from any server or laptop with access to your database, and leave the agent and CLI running as Docker containers.
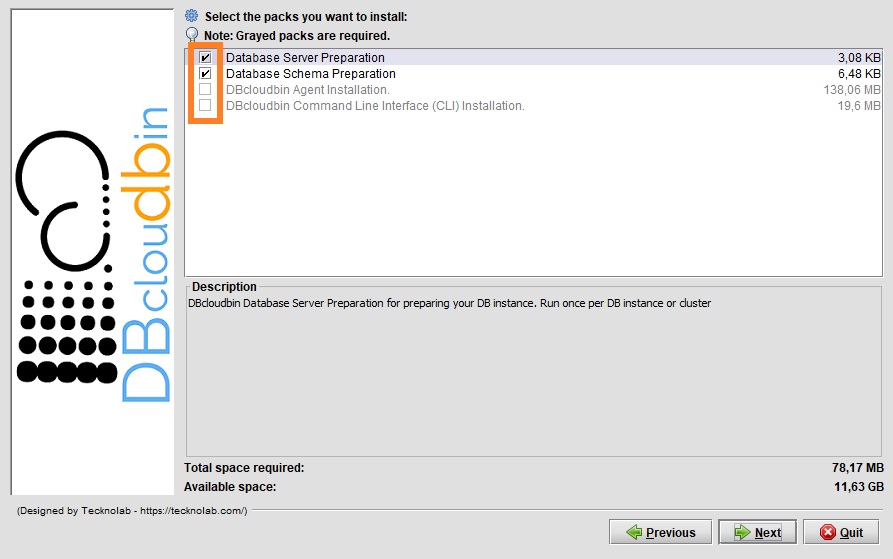
If you want to know how you can use our Docker images, follow the instructions explained below:
Agent
We need to pass in the docker run command the DBcloudbin configuration database as environment variables and an external port if we want (and we should, otherwise the database would not be able to connect with our agent) to expose the docker internal agent port 8090. The available environment variables are:
- DB_TECH: The database technology. By default ORACLE. Accepted MSSQL for SQL Server environments.
- DB_HOST: The database server host. By default, “oracle”
- DB_PORT: The database server port. By default 1521.
- DB_SERVICE: Only for Oracle connections. the listener service. By default, XEPDB1
- DB_PASSWORD: Database password credentials for the DBCLOUDBIN user created during setup.
- DB_CONNECTION: Only for Oracle, as alternative to the DB_HOST, DB_PORT and DB_SERVICE parameters we can define the full database connection (in a jdbc connection string, it would be everything at the right of “jdbc:oracle:thin@”, excluding this prefix).
The command to run it will be:
Sample agent launch command
docker run –rm -d –name dbcloudbin-agent -p8090:8090 -e DB_HOST=mydbhost -e DB_SERVICE=ORCLPDB -e DB_PASSWORD=”myverysecret-password” tecknolab/dbcloudbin-agent:3.04.02
IMPORTANT! Our running agent must be reached by our DB host using the name and port defined when we run the setup tool. If this is no longer the case, we need to adjust the address so that our database host is able to correctly resolve the name and port to access our Docker infrastructure and container, use the DBcloudbin setup again in update mode to reconfigure the name and port.
Command Line Interface (CLI)
After running the DBcloudbin agent, probably we will want to launch some DBcloudbin command using the CLI. To do it with a docker CLI container, it is very simple. There are a few environment variables you may need to use:
- AGENT_HOST: The host (or container name) where the agent is running. By default, “dbcloudbin-agent”.
- AGENT_PORT: The advertised agent port, by default 8090.
- AGENT_PROTOCOL: The protocol used to connect to the agent. By default, “http” but depending how you are using your Docker/Kubernetes infrastructure, you may be using a https network load balancer, so this parameter would be set to https.
Use the CLI with a docker command as the following (for connecting with an agent launched as described above):
Sample CLI command
docker run –rm -it tecknolab/dbcloudbin-cli:3.04.02 info
With the first launch, a CLI wizard will request us the target database credentials (that is the credentials of your application schema, the one selected in the setup for generating the transparency layer). To avoid introducing your database credentials every time you execute a DBcloudbin command, you must add an external docker volume mapped to the /profiles path.
Sample with external profiles folder
docker run –rm -it -v /my_profiles:/profiles tecknolab/dbcloudbin-cli:3.04.02 info
You can find the DBcloudbin Docker images in our Docker Hub repository (https://hub.docker.com/r/tecknolab).

by | | blog
DBcloudbin 3.04 added some new and cool functionalities to our solution. If you need a basic understanding on what DBcloudbin is before going through the new features, you have a solution overview section that cover the fundamentals and a DBcloudbin for dummies post series that goes one step back using a less technical language. For the “why DBcloudbin?” you may want to review our DBcloudbin vision post.
In version 3.04 we are introducing some important features that enhances our vision of simplicity and automation:
- Archive/Delete automation: Until version 3.03.x, archiving operations must be launched with DBcloudbin commands (CLI) manually or in a regular way with your preferred scheduler. With version 3.04.x, we offer an “install and go” solution, usable from the very first second, introducing the Archive/Delete Automation feature. When activated during setup or through configuration, DBcloudbin will automatically archive the new inserted or updated data; and/or delete (with the configured lagging days) the application deleted objects (both archive and delete can be activated independently). This feature can be enabled globally or at table level, so it allows us to activate the auto archive mechanism only for desired tables. This feature does not disable the current archive mechanism, so, for example, we could launch archive jobs manually to migrate the old data, and let the system automatically archive new data with the auto archive functionality enabled.
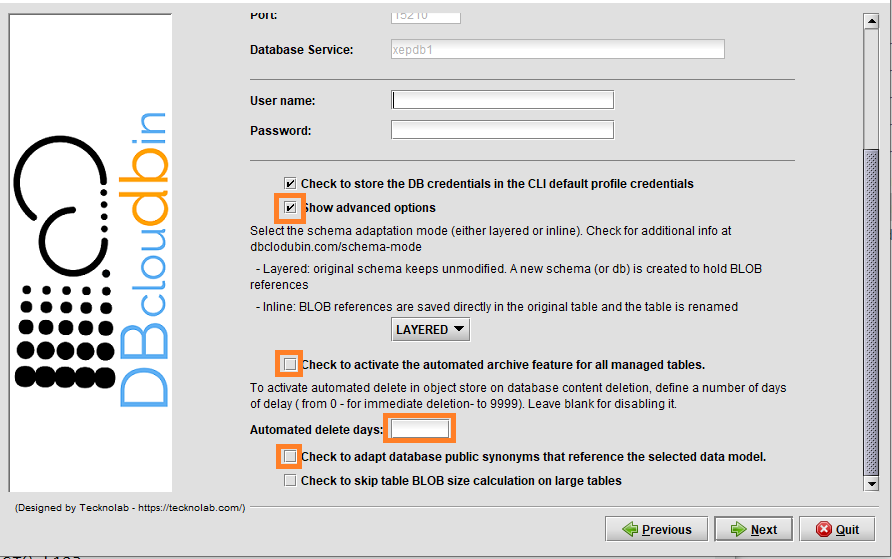
- Public synonyms redirection: DBcloudbin in default mode, creates a new schema (database in SQL Server) for the transparency layer avoiding any change in your original application data model. Depending on your application data layer design, it may not use a single database user for accessing the application data, but several ones (potentially one per application user), referencing the tables and other database objects through public synonyms. In this case, the way to ‘activate’ DBcloudbin is not changing the database connection but changing the affected synonyms to point to the transparency layer instead of to the application schema. This operation might be cumbersome and error prone when addressing complex schemas. DBcloudbin v3.04 addresses this problem with a new option (as highlighted in the previous screen), to automatically reconfigure the existing public synonyms pointing to the application schema. This way, after DBcloudbin setup, the environment will be ready for archive operations without any additional reconfiguration. As a bonus benefit, in the case of uninstalling DBcloudbin, the reverse operation will be also automatically executed.
- Metadata enrichment: In current times, metadata is very important, since it adds value to our data, allowing us to classify, analyze, search and a long list of additional operations that we could carry out with our data. The vast majority of object store infrastructure out there, support some type of metadata assignment to stored objects, that can be leveraged by different analysis tools with the strong benefit of offloading that work from the main application database. For this reason, with this new version, DBcloudbin allow us to add custom metadata defined by the user and based in SQL syntax queries over our database information. The metadata mechanism will allow us to define metadata form the DBcloudbin CLI tool (with -metadata option), with simple queries over the target table or more complex queries using the -join option to obtain metadata from different tables. Also, we could define alias for our metadata, using an expression like the following: {MY_ALIAS}. Additionally, the solution will store a Json file in the same object store path with, not only the custom metadata, but also the Built-in metadata associated to the original object. An example for that could be:
CLI example
dbcloudbin archive MYTABLE -metadata “CONTENT_NAME{FILENAME}, CREATOR{AUTHOR}”
In the previous example we are assuming that our table “MYTABLE” has an attribute “CONTENT_NAME” that we want to be mapped in our object store with its value in the tag “FILENAME”; the same for “CREATOR” (table attribute) and AUTHOR (object store tag name). This is the simplest way of metadata enrichment. The solution is more versatile. It supports any valid SQL expression, not only plain attributes. So if we are using Oracle and the attribute CONTENT_NAME may have uppercase and lowercase characters and we want our tag to hold only uppercase, we may use the following command:
Using expressions
dbcloudbin archive MYTABLE -metadata “upper(CONTENT_NAME){FILENAME}, CREATOR{AUTHOR}”
And there is more. Sometimes we need complex expressions or values where part of the information is not stored at the table we are archiving content from. For enabling that content, you can use a JOIN expression that logically links that data with the specific row in the to-be-archived table content. So if in the previous example, “CREATOR” in table MYTABLE is just and internal id, but the real creator’s name is in the table CREATORS we could use the following archive command:
Using joins
dbcloudbin archive MYTABLE -metadata “upper(CONTENT_NAME){FILENAME}, CREATORS.FULLNAME{AUTHOR} -join “CREATORS ON CREATORS.ID=MYTABLE.CREATOR”
Special shortcuts like @PK (will define the complete primary key as metadata) or @ALL (will define all the target table fields as metadata) are allowed to define metadata in a simpler way.
Special shortcut expressions
dbcloudbin archive MYTABLE -metadata “@PK”
- Improved monitoring: We have included all auto archive information in the DBcloudbin CLI info command, adding last execution information like the total processed objects and execution time or the specific error messages if something is wrong. To get it, we will use the -verbose option. Additionally, this new version includes the -format json option to get a Json friendly output, very useful for scripting and automation processes.
- Docker/Kubernetes support: New version comes with the support of containerized packaging for our agent and CLI, so that it makes it very simple to deploy DBcloudbin agent in Kubernetes clusters or Docker environments. We will discuss this in greater detail in a specific post in our blog.
There are some other minor features that can be checked in our release notes but these are the most relevant.

by | | blog

Big Data collection is taking center stage with people and businesses rapidly shifting to digital technologies amid the COVID-19 crisis. Big Data refers to the massive amounts of unstructured or semi-structured data collected over time from social networks, RFID readers, sensor networks, medical records, military surveillance, scientific research studies, internet text and documents, and eCommerce platforms to name but a few. By 2026, the global market for Big Data is expected to be worth $234.6 billion.
Experts are predicting that Big Data can revive the economy and help businesses thrive. When collected, stored, and analyzed properly, it allows organizations to glean new insights. However, there are also limitations to Big Data analytics. If a business is amassing Big Data without a concrete strategy, all that data may end up unused or even underutilized.
Three Benefits of Downsizing Big Data Analytics
With Big Data, some companies have a “more is better” mentality, which isn’t necessarily the best approach. Modern businesses need data to gain insights and make better decisions, but injudiciously collecting data can be unhealthy and costly for the organization. So, here are three benefits of downsizing your Big Data analytics:
- Increase focus on data quality: Big Data analytics requires quality datasets to solve important problems and answer critical questions. It won’t be able to fulfill its intended purpose if the data is incorrect, redundant, out of date, or poorly formatted. It’s necessary to “clean” and prepare data; otherwise, it won’t work, even with the best practices in real-time analysis.
- Minimize resources needed to maintain databases: Massive datasets naturally require vast storage arrays for optimal computing power, speed, and security. Although data storage options are expanding, most warehoused data solutions can cost millions of dollars to maintain and operate – these data centers require huge amounts of electricity to run and to cool. Having more data means spending more on storage.
- Improves ability to transform data into actionable insights: It’s difficult to derive truly valuable information from an infinite pool of data points, which could be as varied as each unique customer you serve. You don’t need more data; you need the right data. Downsizing your database allows you to maximize the information available to you and create comprehensive, targeted customer profiles on a granular level.
How to Start Downsizing Big Data
Around 80% of a data scientist’s job revolves around getting data ready for analysis, so it’s unsurprising that most top data analysts have advanced degrees in math, statistics, computer science, astrophysics, and other similar subjects. However, the role is ideal for anyone who is curious and has strong problem-solving skills. Many colleges and universities have produced graduates who fit the criteria, so businesses won’t have a hard time finding someone with the right credentials to improve their Big Data analytics processes, despite COVID-19.
Of course, given the intricacies of Big Data, it certainly helps to hire a team that already has prior knowledge and experience with data, including a data scientist. Their understanding and application of Big Data make the specialization one of the most in-demand careers in data analytics today. These specialists are taught to apply advanced analytics concepts, like combining operational data with analytical tools. This allows them to easily determine how best to reach an audience, increase engagement, and drive sales. Having these Big Data scientists on your team can provide you with more insights and guide you to making more informed decisions.
Alternatively, you could choose a third-party solutions provider to help you downsize your database. DBcloudbin is a transparent and flexible solution that selectively moves your heaviest data into an efficient cloud storage service. Some benefits of a database downsizing solution include significant infrastructure cost savings, simplified backup, and stronger analytics performance.
To learn more about DBcloudbin’s features, try our promotional free service today.
Editorial written specially for dbcloudbin.com
by Jianne Brice

by | | blog
In a previous post we discussed about using OCI object storage with DBcloudbin. Since v. 3.03, the solution supports Oracle ‘s Autonomous DB, its flagship Cloud database product. Autonomous adds some new and interesting features, as its DBA automation capabilities, while defining some subtle differences with a plain/old Oracle Std or Enterprise on-premises implementation. Those restrictions and limitations make a non-obvious task implementing a tightly integrated solution as DBcloudbin, so let’s go trough a step by step process. For the regular DBcloudbin implementation procedure, you can check here or visit the Install guide in your customer area.
NOTE: It is out of the scope of this article to discuss about the networking and network security aspects of OCI. As in any DBcloudbin implementation, you will have to ensure connectivity from the DB instance to the DBcloudbin agent and viceversa. Check with your OCI counterpart for the different alternatives to achieve this.
Autonomous DB requirements.
The most relevant differences from a DBcloudbin implementation point of view, are:
- Use of wallet-based encrypted connections. Autonomous DB requires the use of a ciphered connection that is manage through a wallet. When setting up the DBcloudbin to DB connection in the setup tool, you will need to specify your wallet info. More details later on.
- DB to DBcloudbin connection through an https connection only. Autonomous DB restricts the outbound connections that the DB can do to external webservices (as those provided by the DBcloudbin agent). It is required an https URL using a valid certificate from a specific list of certification authorities (so you cannot use a self-service certificate). This requirement has more impact that the previous one, so we will concentrate our detailed configuration to overcome this limitation.
Wallet-based connections
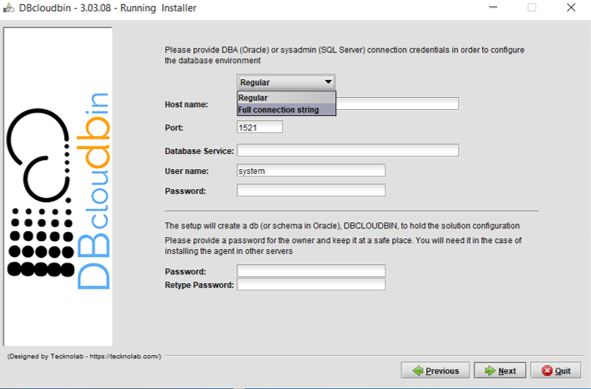
When provisioning an Autonomous DB in Oracle Cloud Infrastructure (OCI), you will generate and download a zip file with the wallet content for ciphered connections to that DB. Just copy the wallet to the server(s) where DBcloudbin will be implemented and extract its contents in a folder with permissions for the OS ‘dbcloudbin’ user (as /home/dbcloudbin/wallet). Then, when executing the DBcloudbin setup tool, select the option “Full connection string” instead of “Regular“. This can be used not only for Autonomous DB connection but for any scenario where we want to provide a full connection string as, for example, when using a Oracle RAC (Real Application Cluster) and specifying the primary and standby connection. In this case, we can simply specify a wallet based connection as <dbname>_<tns_connection_type>?TNS_ADMIN=<wallet_folder> (e.g., “dbdemo_medium?TNS_ADMIN=/home/dbcloudbin/wallet“). Check the details of Autonomous DB connection strings here.
Configure https connections to DBcloudbin agent
Autonomous DB will only allow outbound webservices consumption through https connections using ‘legitimate’ certificates. This will impact in two specific DBcloudbin setup configuration/post-configuration steps:
- We need a valid certificate (not self-signed).
- We need to configure the agent connection through port 443.
If we do not want to use (and pay) a trusted certification authority certificate, we can use the valid workaround of passing the DB to DBcloudbin requests through a OCI API Gateway created for routing the autonomous DB requests to our installed DBcloudbin agent. Since the OCI API Gateway will use a valid certificate, we can overcome this requirement. But, let’s go step by step and start by installing DBcloudbin.
Go to the host you have provisioned for installing DBcloudbin (we are assuming it is hosted in OCI, but this is not strictly necessary; however, it is supposed to be most common scenario if we are implementing DBcloudbin for an Autonomous DB) and run the setup tool. In the “Agent address selection” screen, overwrite the default value for the port, and use the standard 443 for https connections. If you will use a legitimate certificate (we recommend to install it in a OCI network balancer instead of in the DBcloudbin agent) and you already know the full address of the network balancer you will use to serve DBcloudbin traffic, use the address in the “Agento host or IP” field. If you are going to use an API Gateway, at this point you still do not know the final address, so just fill up anything (you will need to reconfigure later on).
At this point, we should have DBcloudbin installed, but it is unreachable, even through the CLI (dbcloudbin CLI command is installed by default in /usr/local/dbcloudbin/bin folder in a Linux setup). We have setup DBcloudbin so that the agent is reached by https in standard port 443, but we are going to setup the ‘real’ service in the default 8090 port, using http (if you want to setup an end-to-end https channel, just contact support for the specific instructions). So, let’s overwrite the configuration by editing the file application-default.properties in <install_dir>/agent/config. Add the property server.port=8090 and restart the service (e.g. sudo systemctl restart dbcloudbin-agent). At this point (wait a couple of minutes for starting up) we should be able to connect to “http://localhost:8090” and receive a response “{“status”:”OK”}“. This shows that the agent is up&running.
We need to overwrite in our CLI setup the dbcloudbin agent address, in order to connect to it. So edit the file application-default.properties at <install_dir>/bin/config/ (should be blank, with just a comment “# create”). Add in the botton the following lines:
# create
dbcloudbin.endpoint=http://localhost:8090/rest
dbcloudbin.config.endpoint=http://localhost:8090/rest
Execute a “dbcloudbin info” command (at <install_dir>/bin) to check that the CLI is now able to contact the agent and receive all the setup information.
We also need to instruct DBcloudbin that invocations from Autonomous DB to the agent will be through https. This is configured with the following setting:
dbcloudbin config -set WEBSERVICE_PROTOCOL=”https://” -session root
Set wallet parameter
When using a https connection with Oracle, DBcloudbin will read the optional parameters ORACLE_WALLET and ORACLE_WALLET_PWD for finding the location of the certificate wallet to be used by the Oracle DB for validating the server certificates. Autonomous DB does not allow the configuration of a private wallet (it just ignores it) but we still need to set this parameters at DBcloudbin level; otherwise any read operation, would fail.
Just execute DBcloudbin CLI config commands for both parameters, with any value:
dbcloudbin config -set ORACLE_WALLET=ignored -session root
dbcloudbin config -set ORACLE_WALLET_PWD=ignored -session root
Setup a API gateway (optional)
Now, it is time to setup our OCI API gateway to leverage the valid certificate https endpoint we will get when exposing our DBcloudbin agent through it. Go to your OCI console and in the main menu, select Developer Services / Gateways. Create a new one.
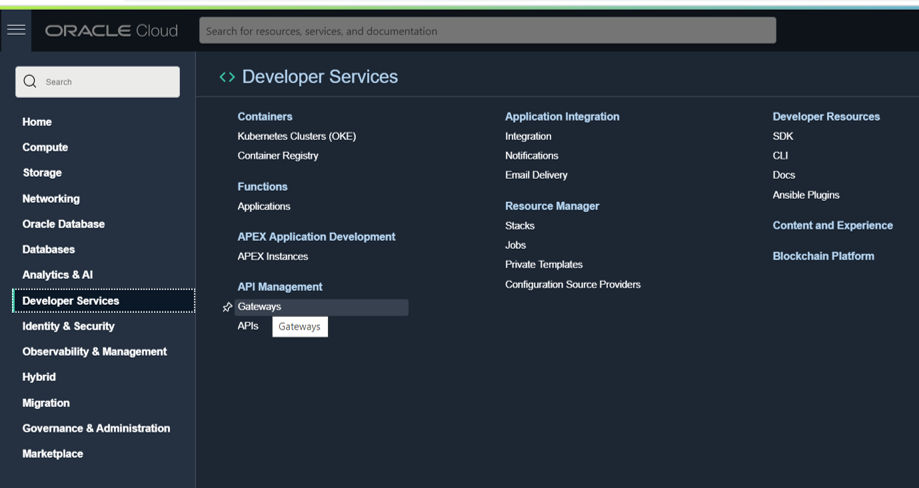
Once created, add a new Deployment (at left-hand side). Give any name (e.g. “rest”) and set as path prefix /rest. Press Next to go to the routes form.
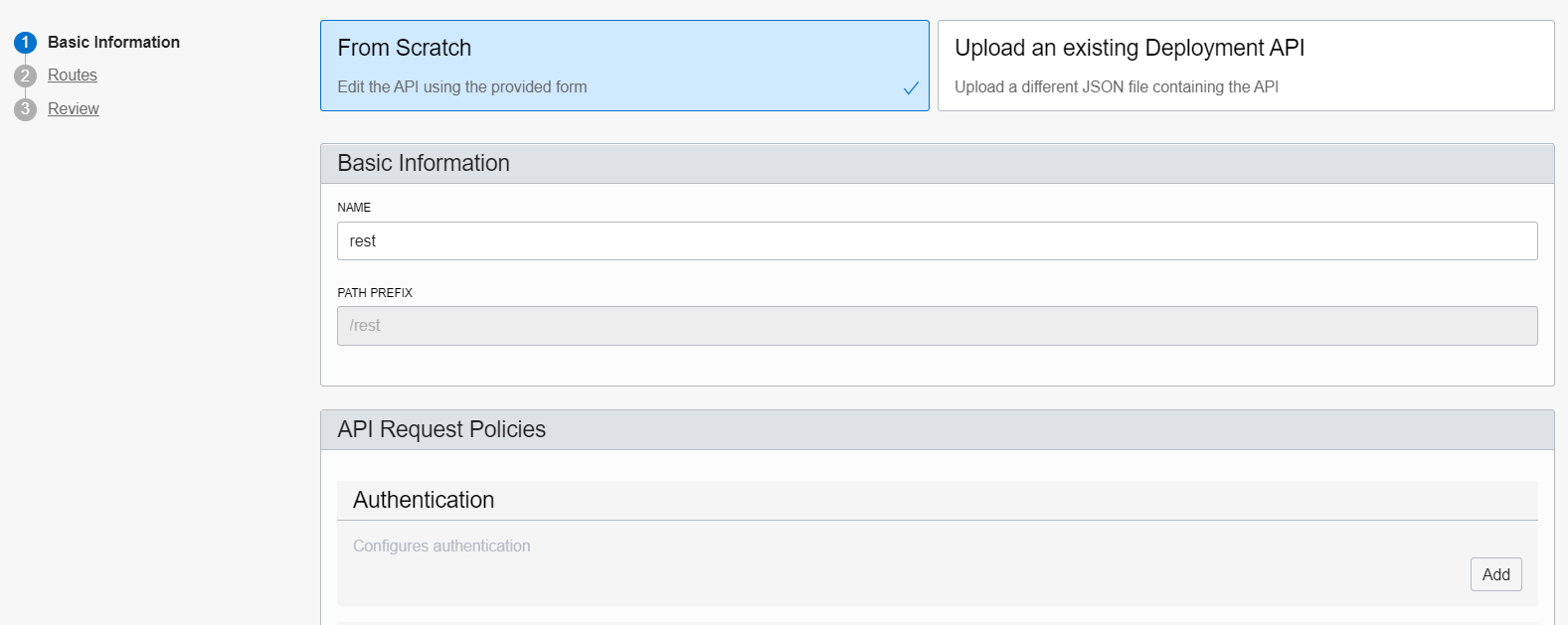
Create a route with method “GET” and path “/blob/read“. Point that route to the URI http://<dbcloudbin-agent-host>:8090/rest/blob/read. See figure below. Confirm the configuration and wait for the API gateway to be configured.
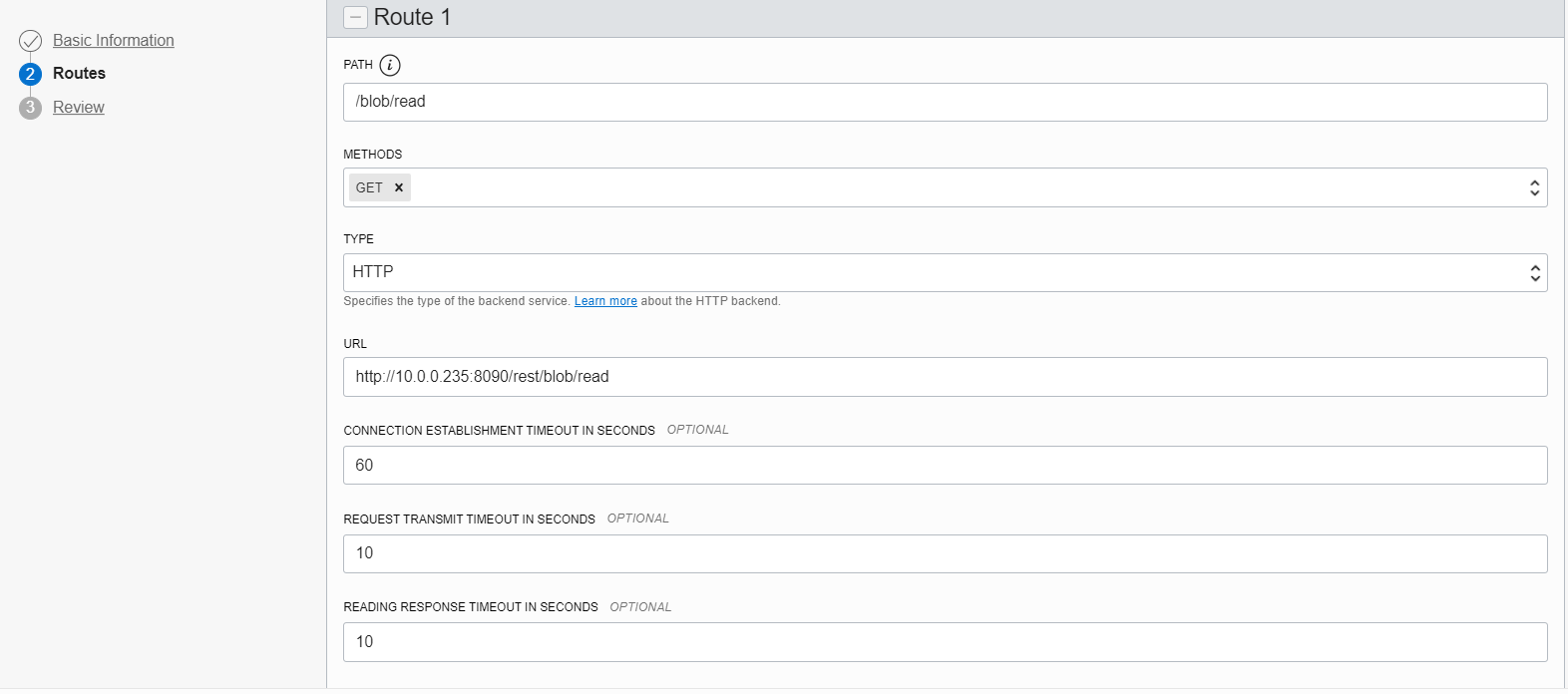
Once ready, check the https URI generated for the API gateway endpoint and test it (for example with a curl command). An invocation to https://<api-gateway-endpoint>/rest/blob/read should return a blank result but should not fail (return a 200 HTTP code). Once this is working, we are ready to finish the setup and have the implementation up&running.
Final step. Reconfigure DBcloudbin endpoint
We need to reconfigure the DBcloudbin agent endpoint in our setup to point to the newly created API gateway https endpoint. So, execute the DBcloudbin setup again, but instead of using the ‘New setup option’, use the “Upgrade SW and DB configuration” (not matter if you are using the same setup version).
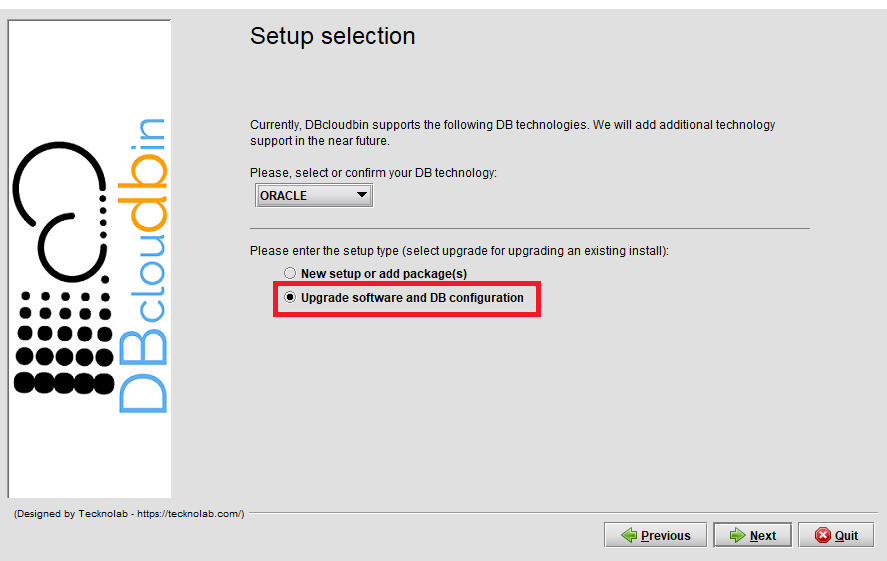
After providing the DB credentials, you will see the agent host and port configuration screen with the host value and port value (443) configured during the initial setup. Change the host value by the API gateway fully qualified host name (e.g. nfbwza67ettihhzdlbvs7zyvey.apigateway.eu-frankfurt-1.oci.customer-oci.com). You will be requested DBA credentials (as the ‘master’ ADMIN user) in order to reconfigure the required network ACL’s to enable communication with the new endpoint.
It is all set. Go to the DBcloudbin CLI and execute a “dbcloudbin info -test” that will test the full environment and DB connectivity. If it works, you are done, is time to reconnect your application through the created transparency layer and start moving content out to your object store. If not, check the error message and open a support request to DBcloudbin support.
Summary.
The Autonomous DB specific restrictions make setting up DBcloudbin a little bit more tricky, but perfectly possible. We can leverage all the product benefits and avoid exponential growth in our Cloud DB deployment as we do with our on-premises environment.
